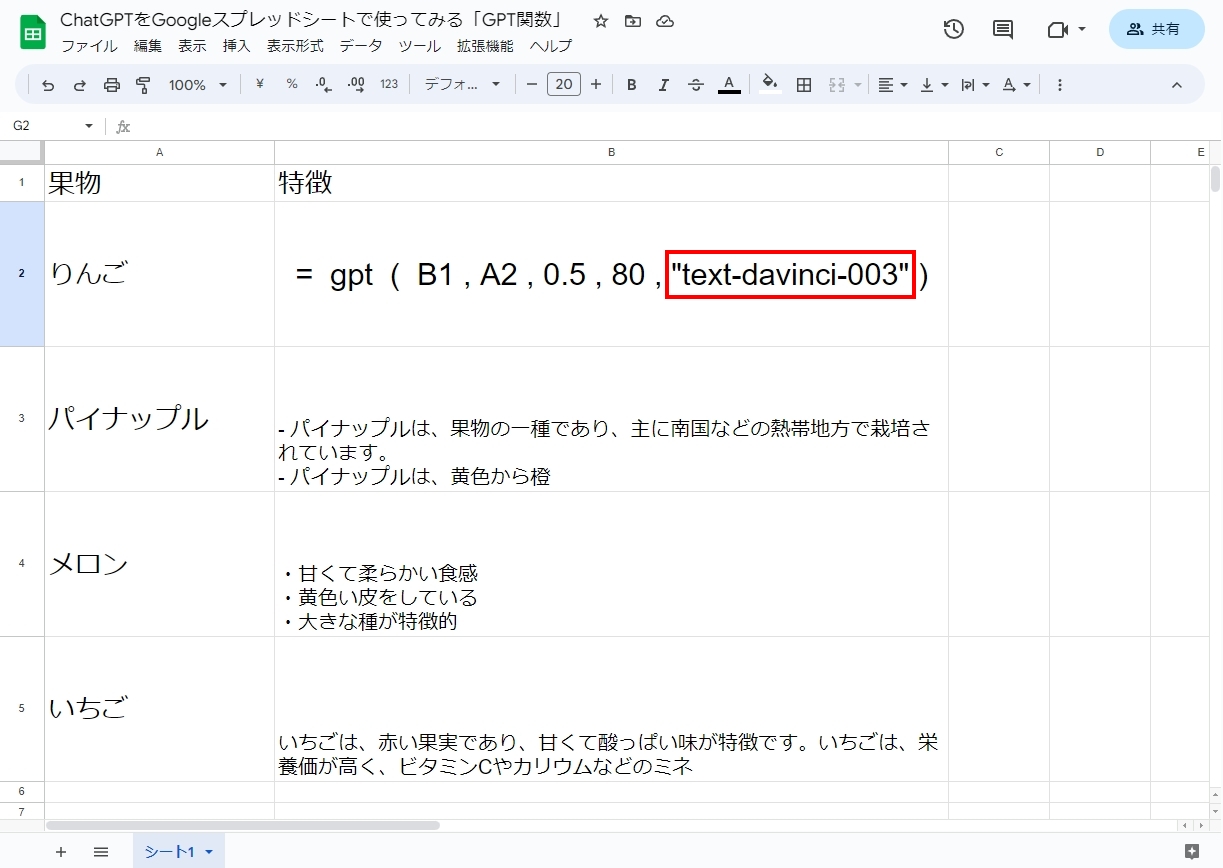
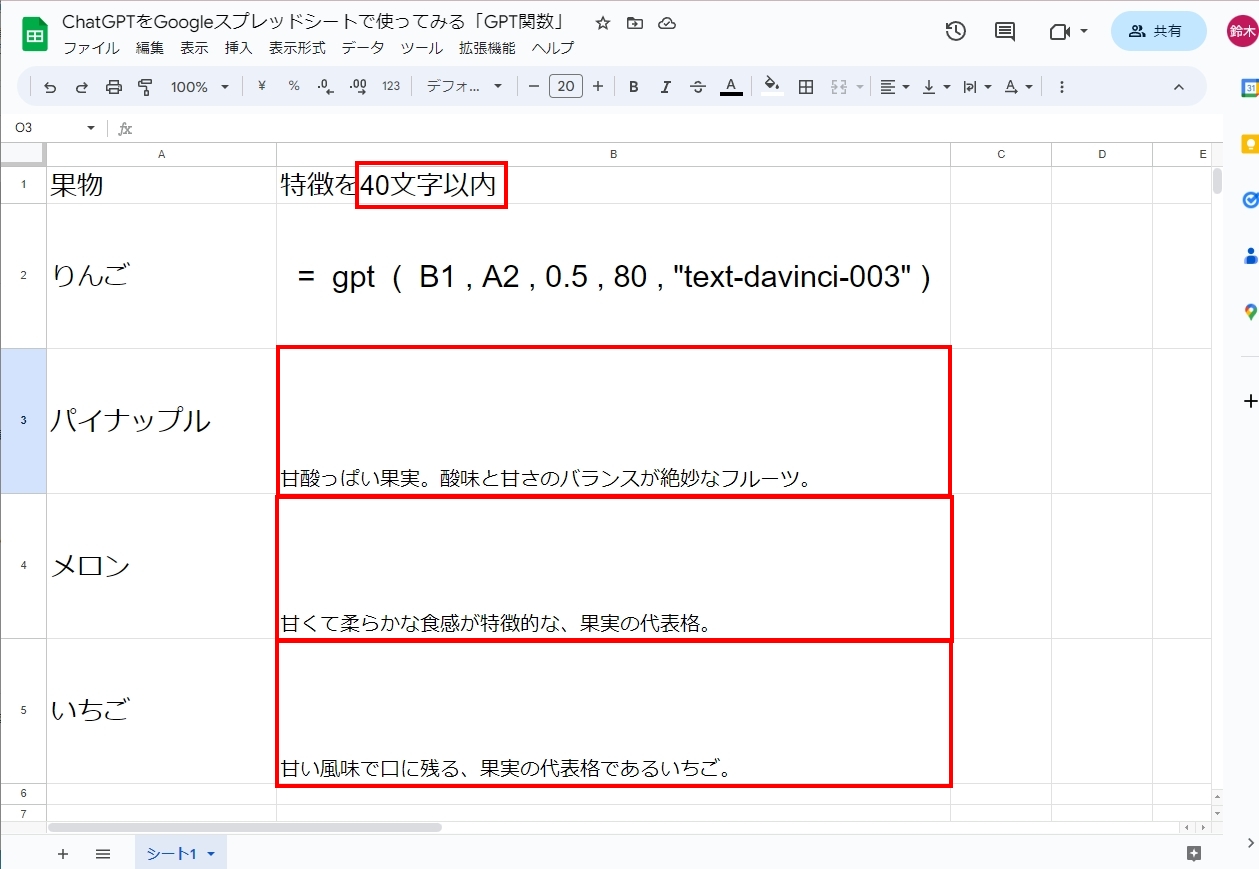
この記事では、ChatGPTをGoogleスプレッドシートで用いて、聞きたいことに対してChatGPTにスプレッドシート内で答えてもらうことをやっていきます。
スプレッドシートでChatGPTを呼び出すためにはGPT関数を使います。
GPT関数を使えるようにするためには、アドオン「GPT for Sheets™ and Docs™」が必要になります。こちらのアドオンの有効化方法については以下の記事にて取り上げています。

ChatGPTをスプレッドシートで使用する「GPT関数」を使うためにはアドオン「GPT for Sheets™ and Docs™」が...
| GPT関数を使うためにはOpenAI APIの有料アカウントが必要です。 |
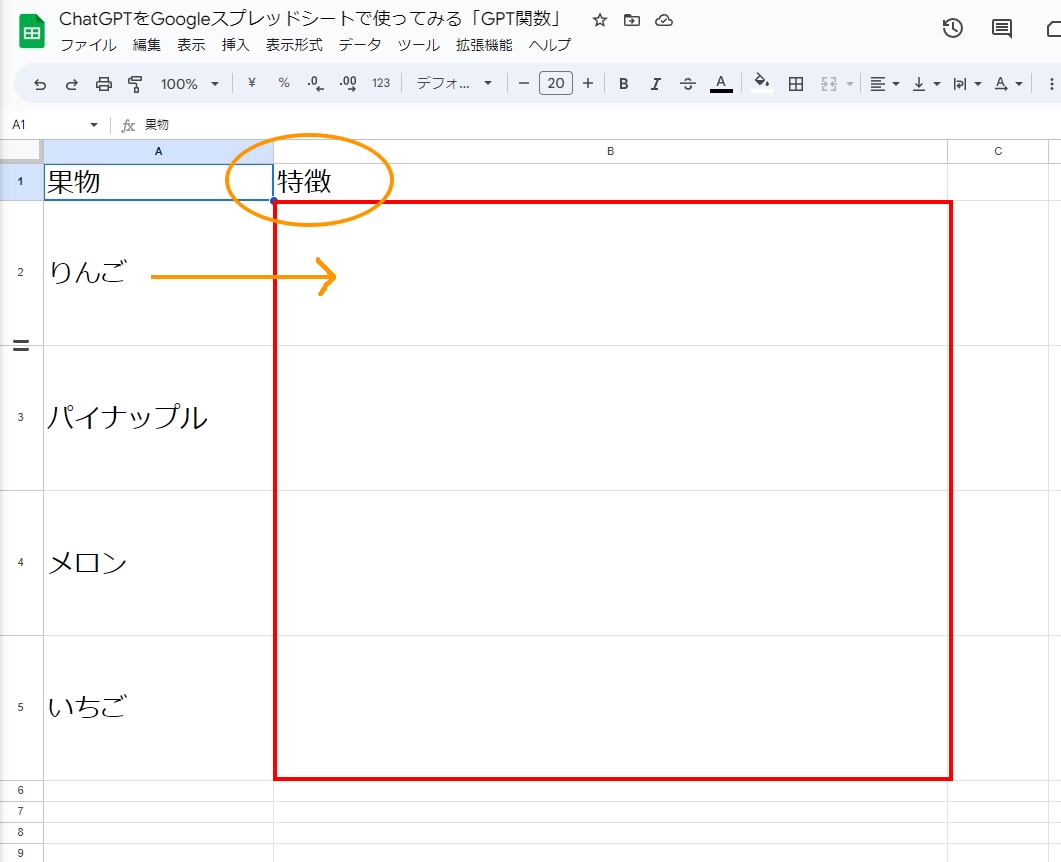
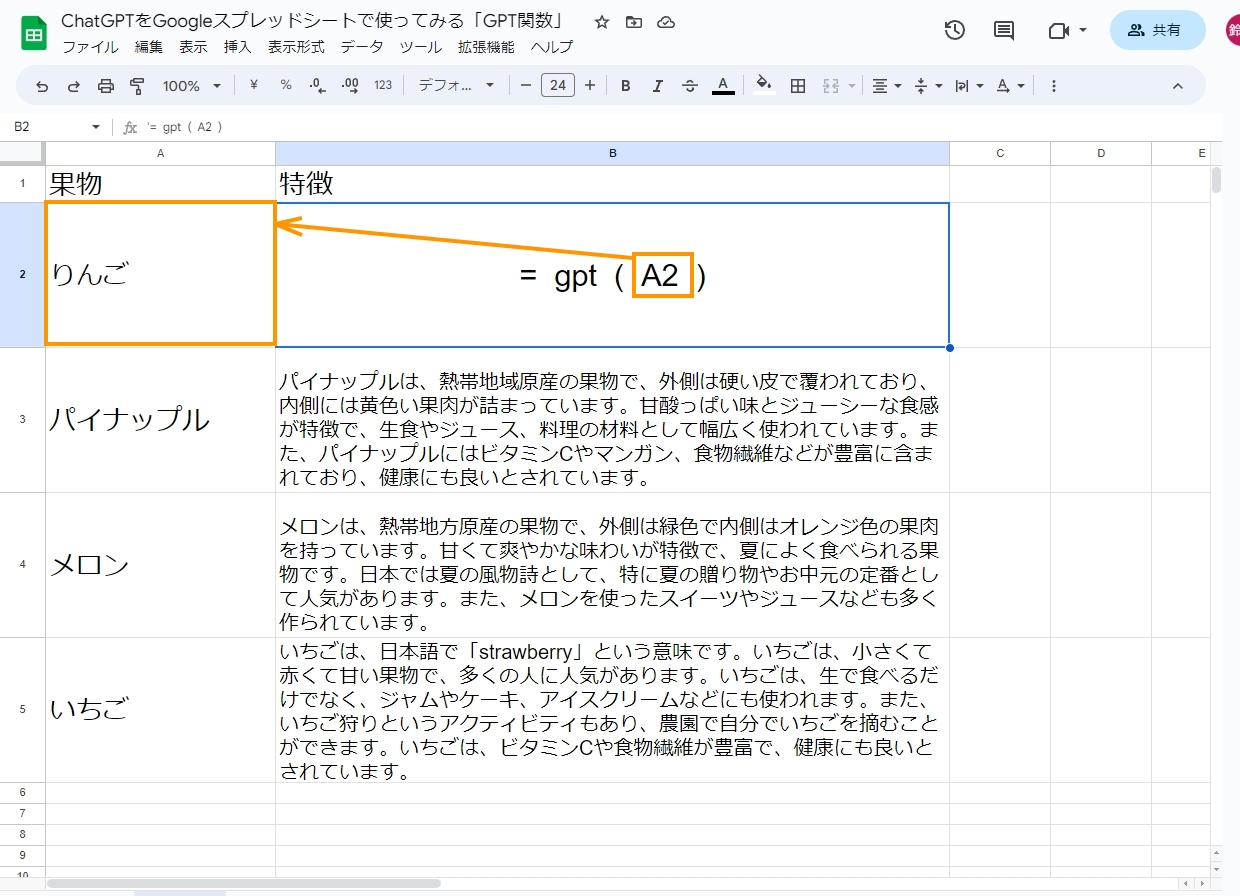
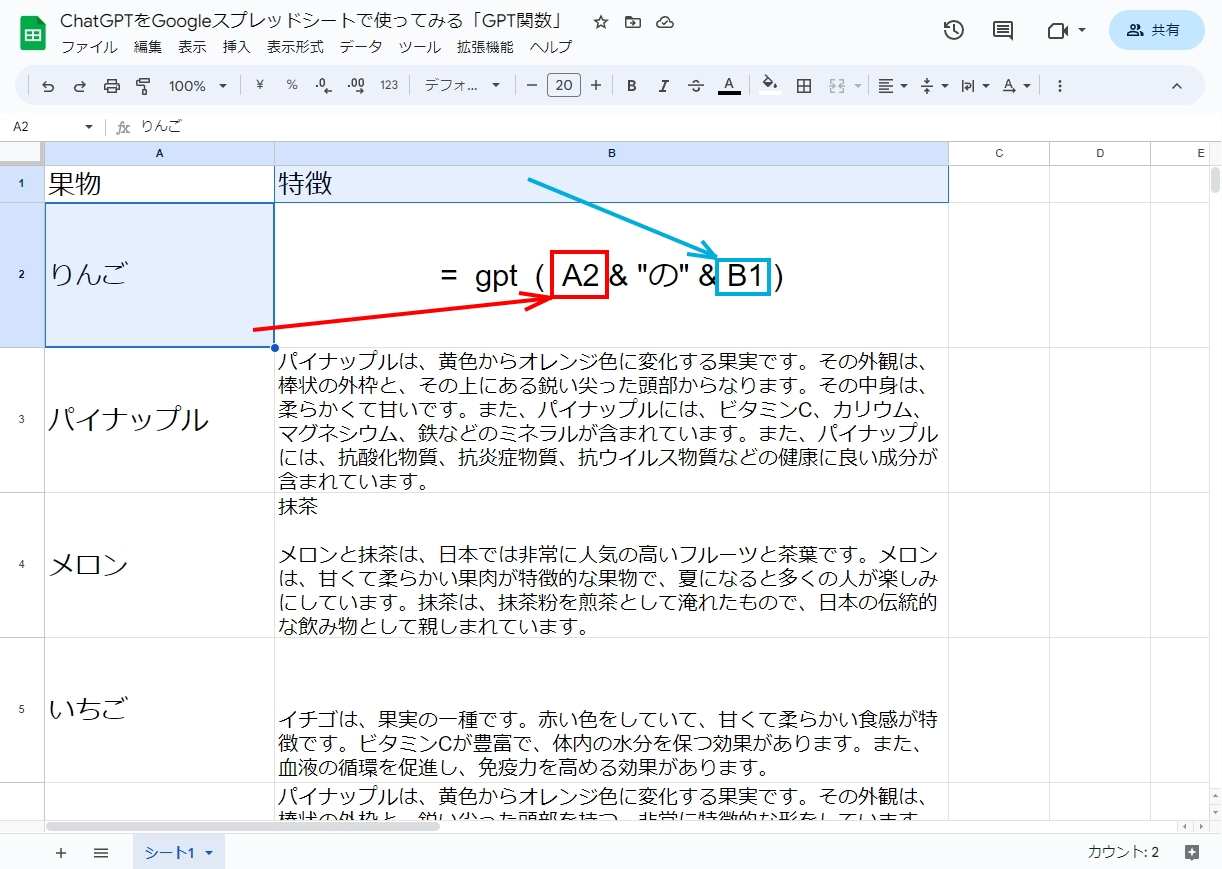
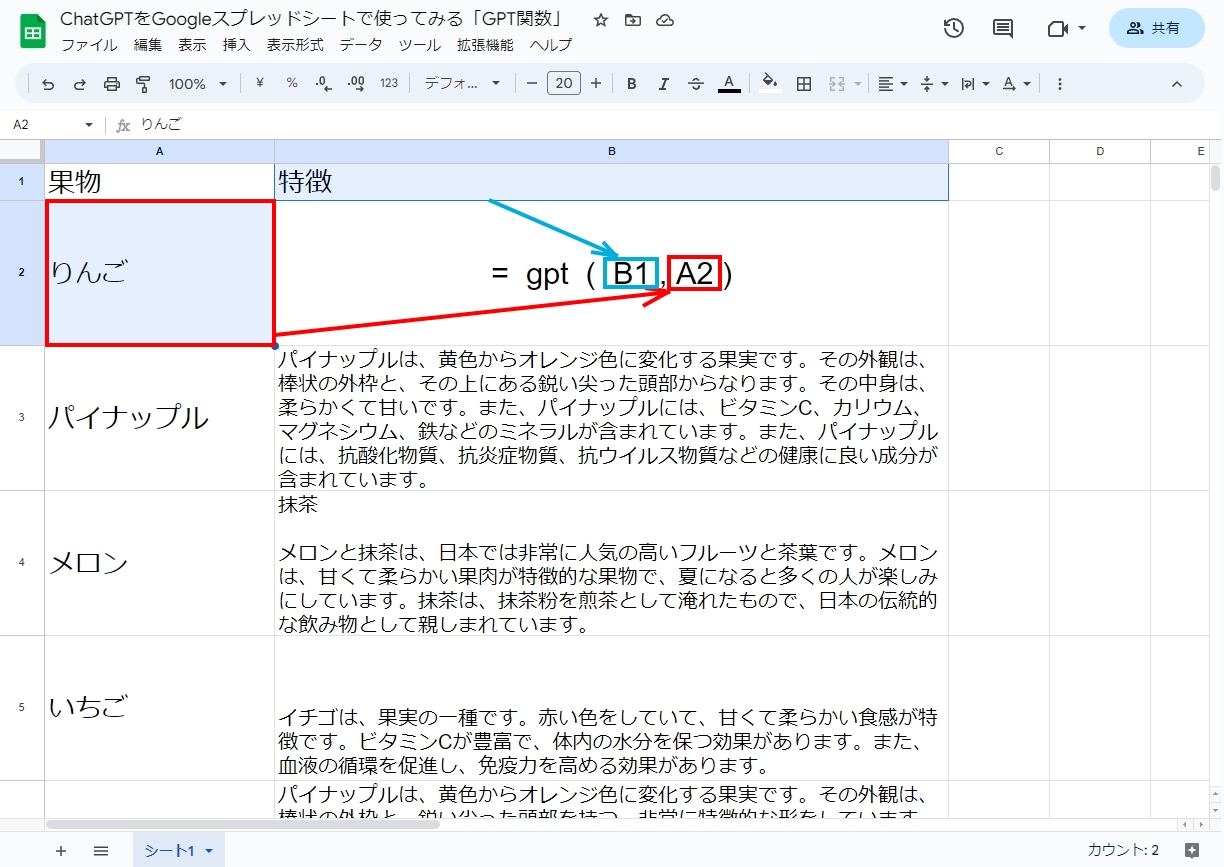
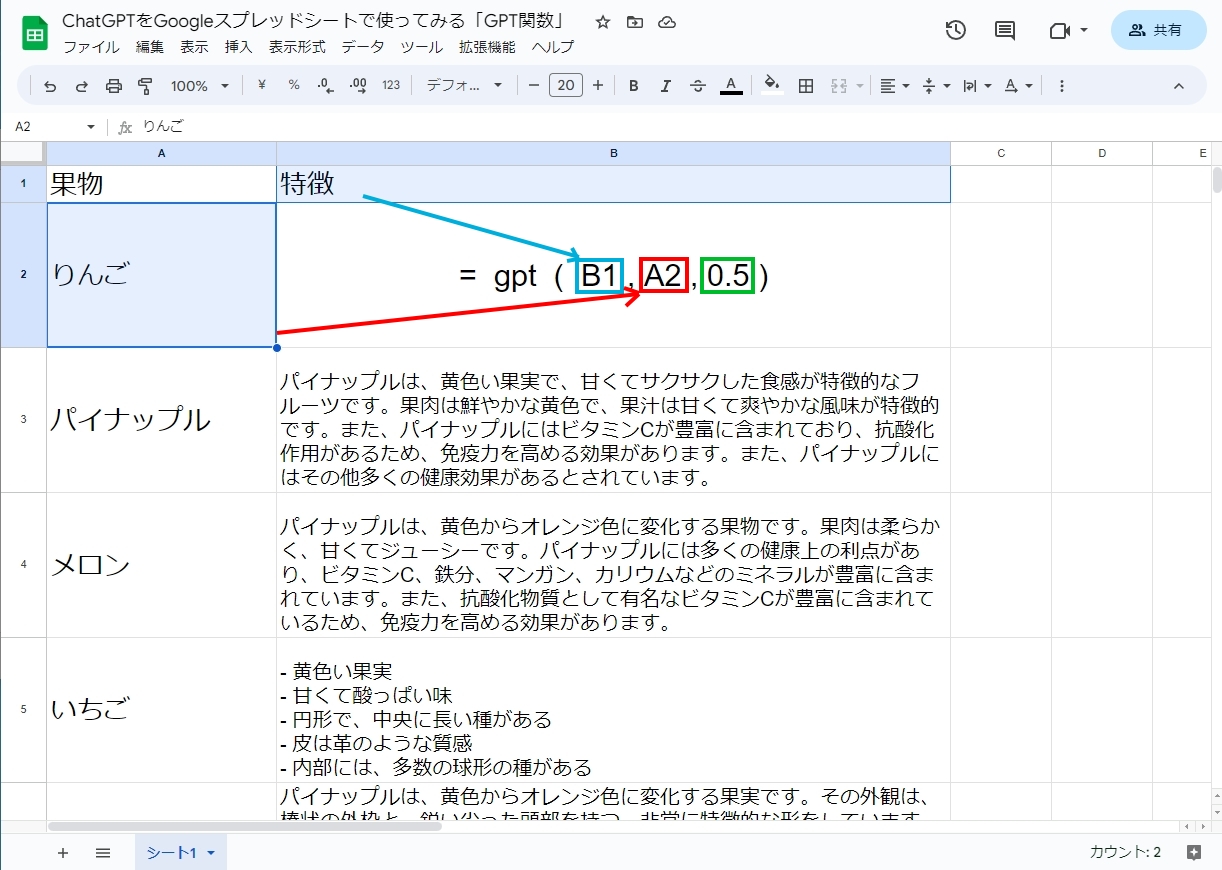
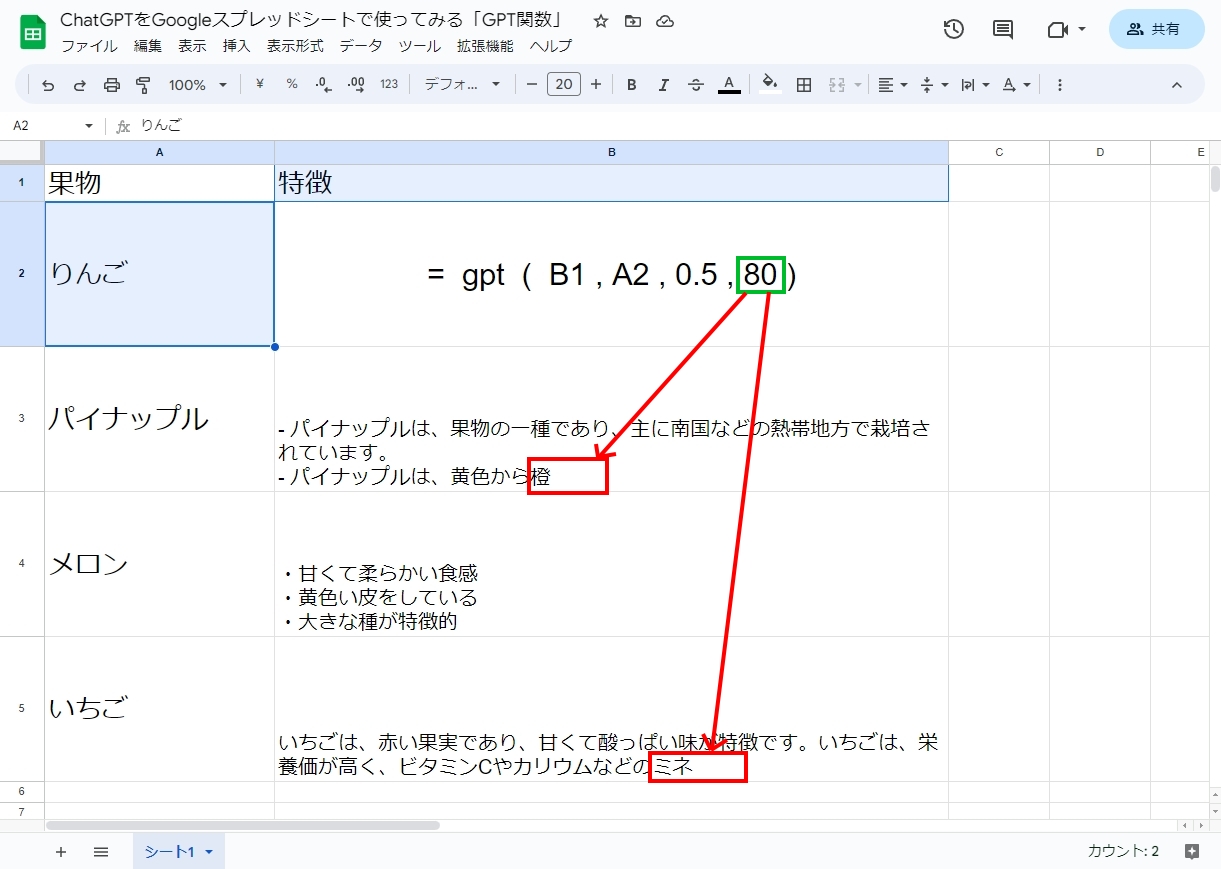
トークンについては以下の記事の一部で取り上げています。

OpenAIのAPIキーは、スプレッドシートで使用するGPT関数をはじめ、ChatGPTチャット画面以外で使用する際に必要となってきま...